В конце октября прошлого года лаборатория искусственного интеллекта Meta* AI представила проект устного машинного переводчика для южноминьского диалекта китайского языка. По словам разработчиков, новая технология даст качественный толчок развитию устных машинных переводчиков для языков, не имеющих стандартизированной письменности. ЭКД рассказывает о ситуации с диалектами в Китае и новой технологии для устного перевода.
На сайте Meta* сообщается, что программа Universal Speech Translator (UST) позволяет осуществлять перевод в паре языков, где один преимущественно используется для передачи устной речи. В качестве пилотного проекта разработчики выбрали пару английский и южноминьский диалект китайского языка. Этот диалект распространен в южных провинциях Китая (в Фуцзяни, на островах Хайнань и Тайвань) и среди китайских диаспор Юго-Восточной Азии.
*Компания Meta признана экстремистской организацией, деятельность в России запрещена
Государственный язык и диалекты
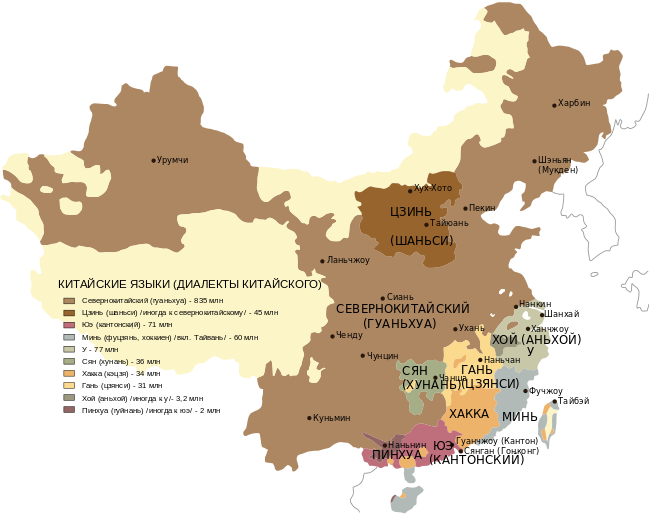
Для разработки программы был взят именно диалект, а не собственно китайский язык. Государственный язык Китайский Народной Республики — путунхуа (普通话 «общераспространенный язык»). В его основу заложены фонетические нормы пекинского диалекта северокитайской диалектной группы. В других районах страны распространены диалекты, которые порой абсолютно непонятны носителям путунхуа, а также языки национальных меньшинств, таких как тибетцы, уйгуры, монголы, вообще не связанные с китайским языком.
После образования Китайской Республики в 1912 году власти стали активно продвигать идею общенационального языка. На сегодняшний день на путунхуа говорят свыше 80% населения страны, на нем ведется весь образовательный процесс, транслируется информация СМИ, он используется в государственных учреждениях.
На остальных шести диалектных группах говорят около 25% китайцев. В рамках каждой диалектной группы также выделяются десятки локальных диалектов. Область использования диалектов постоянно сужается: молодые люди предпочитают говорить на путунхуа, на котором они получают образование и который используют в профессиональной среде. На родном диалекте они обычно общаются только со старшими родственниками.
Южноминьский диалект
Диалектная группа минь (闽官言), охватывающая провинцию Фуцзянь, острова Хайнань и Тайвань, считается одной из наиболее архаичных. По разным подсчетам, общее число носителей диалектов этой группы составляет от 67 млн до 120 млн человек. Выделяются от шести до девяти диалектных подгрупп, к которым относится и южноминьский диалект (闽南话), использующийся в провинции Фуцзянь и на острове Тайвань. На нем говорят примерно 48 млн человек.
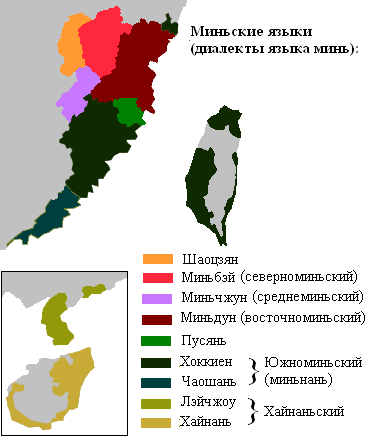
На Тайване южноминьский диалект имеет официальный статус наряду с гоюй (название путунхуа на Тайване), диалектом хакка, а также более чем десятком языков коренного населения острова — тайваньских аборигенов. В этом регионе южноминьский диалект так же называют тайваньский или хоккиен (Hokkien). Его носителями считаются 13,5 млн человек — больше половины населения острова. Тайваньский диалект продолжает доминировать среди старшего поколения, особенно центрального и южного районов острова.
В последние годы в материковом Китае и на Тайване все громче слышны призывы к сохранению региональных самобытных культур, важной частью которых являются местные диалекты. В прошлом упор делался на открытие учебных классов, выпуск специальных радио- или телепередач, но сейчас предпринимается все больше попыток воспользоваться преимуществами современных технологий.
Технологии распознавания и транскрибирования диалектов
Исследования в области разработок технологий устного машинного перевода на основе ИИ ведутся уже несколько десятилетий. Благодаря работе технологических гигантов Google, Microsoft и Baidu приложения для устного перевода стали частью повседневной жизни, но большинство из них имеют в настройках только распространенные языки, такие как английский, немецкий, китайский, русский и т. д. Разработки в области устного машинного перевода китайских диалектов насчитывают всего пару лет и пока не получили должного освещения.
В 2019 году китайская компания Alibaba’s AI Labs заявила о готовности инвестировать $15 млн в обучение своей умной колонки распознавать различные диалекты китайского языка, выбрав сычуаньский диалект для пилотной версии программы. С похожей инициативой выступила группа ученых из северо-восточного Китая. Они надеются, ИИ поможет сохранить почти исчезнувший маньчжурский язык.
Успешный опыт транскрибирования диалектов при помощи ИИ есть и у iFlytek. Благодаря активному участию волонтеров, в приложении были собраны данные по более чем 20 диалектам. Разработчики заявляют, что программа способна распознать не менее 80% диалектной речи. В том же году команда Сямэньского университета в провинции Фуцзянь создала устный переводчик с путунхуа на южноминьский диалект. В 2020 году на Тайване местные ученые создали программу для распознавания тайваньского диалекта и конвертации его в китайские иероглифы.
Первый устный машинный переводчик с тайваньского диалекта на английский язык
В конце октября этого года Meta AI*, лаборатория ИИ компании Meta*, объявила о разработке технологии ИИ, которая позволит осуществлять устный перевод с китайского диалекта на английский язык. Разработчик программы — тайваньский инженер Чэнь Пэнжэнь (陳鵬仁), который выбрал для эксперимента тайваньский диалект. Важно отметить, что для записи этого диалекта используют несколько систем, включающих китайские иероглифы, тайваньские региональные иероглифы и даже латиницу. Ввиду этих обстоятельств, новаторством программы стало то, что устный перевод осуществляется с диалекта, у которого нет стандартизированной письменности.
19 октября 2022 на сайте Meta AI* было опубликовано видео, в котором основатель компании Марк Цукерберг и разработчик технологии Чэнь Пэнжэнь представляют проект Universal Speech Translator (UST). На видео показано, как машинный переводчик в режиме реального времени помогает им общаться на английском языке и тайваньском диалекте.
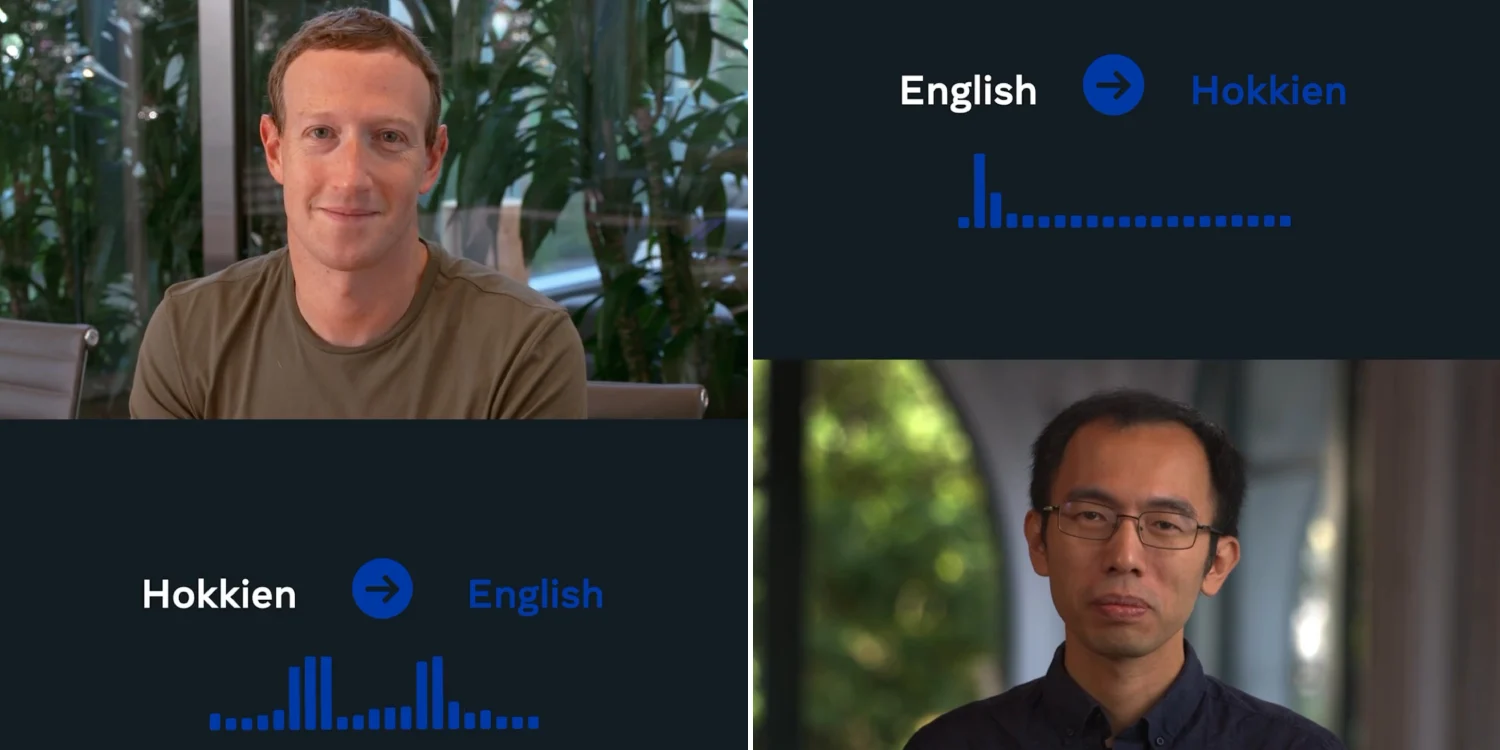
Фото: Meta*
Создатели проекта отмечают, что их цель — упрощение коммуникации между людьми по всему миру:
«До сих пор перевод с использованием искусственного интеллекта был сосредоточен на письменных языках. Однако из более чем 7000 ныне живых языков более 40% являются преимущественно устными и не имеют стандартной или широко известной письменности».
В статье Taipei Times разработчик Чэнь Пэнжэнь, отвечая на вопрос о мотивации, рассказал о стремлении помочь 70-летнему отцу Чэнь Шэнцзяну (陳聖獎) взаимодействовать с англоговорящими людьми. Для многих пожилых людей на Тайване намного комфортнее общаться на их родном тайваньском диалекте.
«Я всегда хотел, чтобы мой отец мог общаться со всеми на родном диалекте. Ему так удобнее», — сказал он.
В процессе разработки исследовательская команда столкнулась с рядом трудностей. Тайваньский диалект — низкоресурсный, то есть у разработчиков недостаточно данных для обучения программы. Им пришлось задействовать китайский в качестве промежуточного языка перевода. Так как выбранный диалект не обладает стандартизированной системой записи, разработчики спользовали технологию преобразования речи без создания транскрибированного текста, как это принято в стандартных переводчиках.
«Мы использовали созданную Meta* технологию перевода речи в единицы (speech-to-unit translation или S2UT) для преобразования входной речи в последовательность акустических единиц, — пояснил генеральный директор компании Марк Цукерберг в своем блоге. — Затем мы сгенерировали звуковые сигналы из этих единиц. Движок UnitY был использован для создания двухпроходного механизма декодирования, где декодер первого прохода генерирует текст на родственном языке (путунхуа), а декодер второго прохода создает единицы».
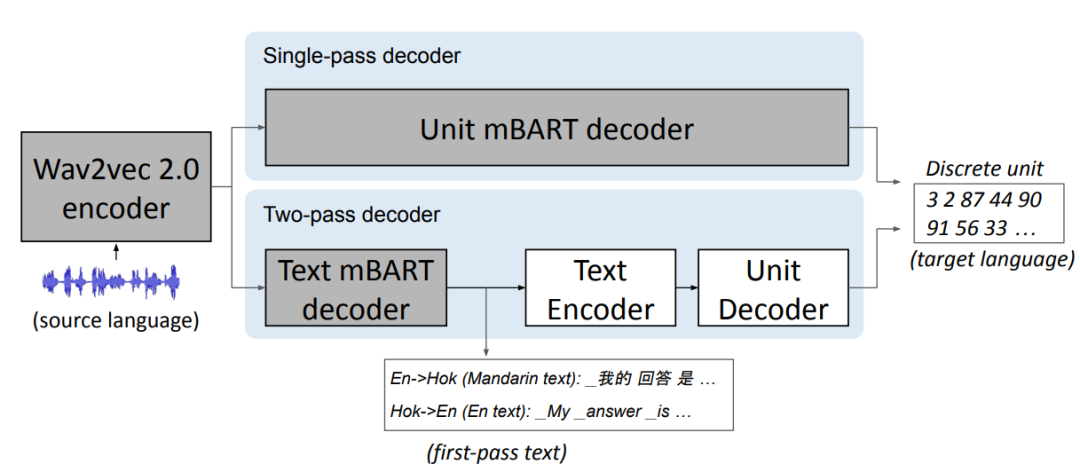
В дополнение была создана система оценки правильности перевода, которая позволяет сравнивать машинный перевод с переводом, выполненным человеком. Пока программа может переводить только одно предложение за раз. Тем не менее, это уже впечатляющий результат для устного переводчика с диалекта.
Реакция китайских интернет-пользователей и дальнейшие перспективы
Большинство китайских интернет-пользователей встретили новость о создании переводчика с большим интересом. Комментаторы предложили создать аналогичный переводчик для других диалектов китайского языка, в частности, для вэньчжоуского диалекта. Из-за архаичной фонологии он считается крайне сложным для понимания даже внутри диалектной группы у, к которой он относится. Кто-то посетовал, что даже в китайских приложениях функция распознавания южноминьского диалекта пока отсутствует.
Тестируя сайт, созданный Meta*, тайваньский YouTube-комментатор И Гэ (壹哥) отметил, что пока программа часто тормозит и выдает неточный перевод. Но это неудивительно для только что запущенного продукта.
Говоря о недостатках программы, разработчик Meta* Фань Хуэйхуэй (范蕙蕙) отметила:
«Система перевода по-прежнему сталкивается с некоторыми проблемами. Низкая скорость, невозможность передать интонацию, сделать речь непринужденной и т. д. Мы продолжаем активную фазу исследования и считаем, что в течение двух-пяти лет сможем не только значительно улучшить качество перевода, но и поддерживать больше языков».
Она также считает, что в будущем новая технология, предложенная Meta*, позволит сотням миллионов людей во всем мире получить доступ к онлайн-информации на их родном языке.
«В настоящее время несколько языков доминирует в области онлайн-информации. Система перевода посредством искусственного интеллекта не только поможет тем, кто не говорит на этих языках, но и полностью изменит то, как люди во всем мире общаются и обмениваются информацией».
Анастасия Судакова
*Компания Meta признана экстремистской организацией, деятельность в России запрещена.
Подписывайтесь на ЭКД в Телеграме.